
Survey of Small Language Models
Published:
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness
By Fali Wang, Suhang Wang
Abstract: Large language models (LLMs) perform excellently in a variety of tasks but face challenges with time and computational costs due to their large parameter sizes and high computational demands. Therefore, small language models (SLMs), with their advantages such as low latency, cost-effectiveness, and ease of customization, are becoming increasingly popular for use in resource-limited environments and for acquiring domain-specific knowledge. We conducted a detailed survey on the technologies, enhancement methods, applications, collaborations with LLMs, and reliability of small language models. We also explored future research directions and have published a list of related models and articles on GitHub: https://github.com/FairyFali/SLMs-Survey.
Link of the survey: link
Paper Overview
Figure 1 Paper Structure
Challenges of LLMs
Neural language models (LMs) have significantly enhanced NLP, evolving from BERT’s pre-training and fine-tuning paradigm to T5’s pre-training with prompts, and finally to GPT-3’s context learning. Models such as ChatGPT and Llama demonstrate “emergent abilities” when scaled up to large datasets and model sizes, advancing NLP applications in fields like programming, recommendation systems, and medical Q&A.
Despite the excellent performance of large language models (LLMs) in complex tasks, their substantial parameter sizes and computational demands limit their deployment locally or confine them to cloud-based calls. This presents several challenges:
- The high GPU memory usage and computational costs of LLMs typically mean they can only be deployed via cloud APIs, requiring users to upload data for queries, which can lead to data leaks and privacy issues, especially in sensitive areas like healthcare, finance, and e-commerce.
- Using cloud-based LLMs on mobile devices faces issues of cloud latency, while direct deployment is impractical due to the high parameter and cache demands exceeding the capabilities of standard devices.
- The vast number of parameters in LLMs can cause inference delays ranging from a few seconds to several minutes, making them unsuitable for real-time applications.
- LLMs perform poorly in specialized fields like healthcare and law, requiring costly fine-tuning to improve performance.
- Although general-purpose LLMs are powerful, many applications and tasks require only specific functionalities and knowledge, making the deployment of LLMs potentially wasteful and less effective than specialized models.
Advantages of SLMs
Recently, small language models (SLMs) have demonstrated performance comparable to LLMs while offering advantages in efficiency, cost, flexibility, and customization. Due to their fewer parameters, SLMs save significant computational resources during pre-training and inference, reduce memory and storage needs, and are particularly suitable for resource-limited environments and low-power devices. Therefore, SLMs are increasingly gaining attention as alternatives to LLMs. As shown in Figure 2, the download frequency of SLMs in the Hugging Face community now exceeds that of larger models, and Figure 3 illustrates the growing popularity of SLM versions over time.
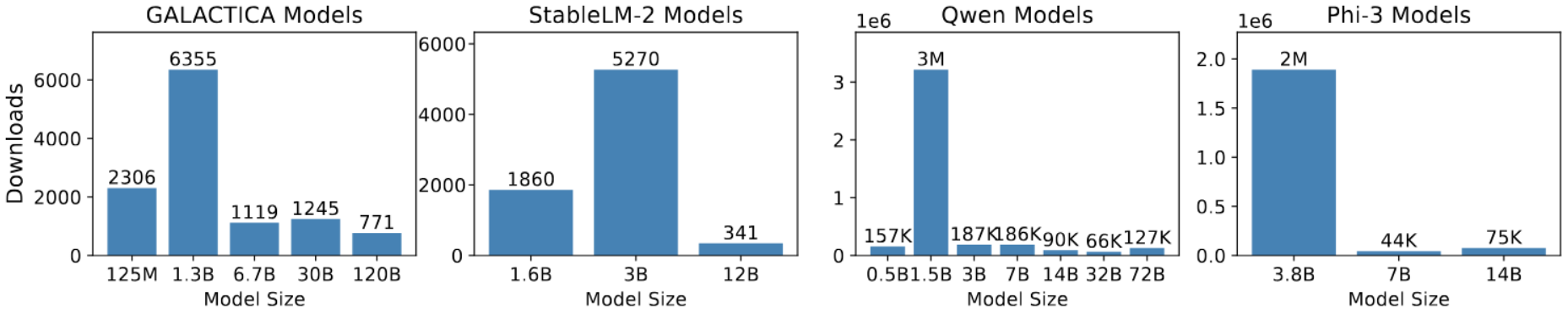
Figure 2 Download Statistics Last Month in Hugging Face for LLMs with Various Model Sizes, obtained on October 7, 2024.
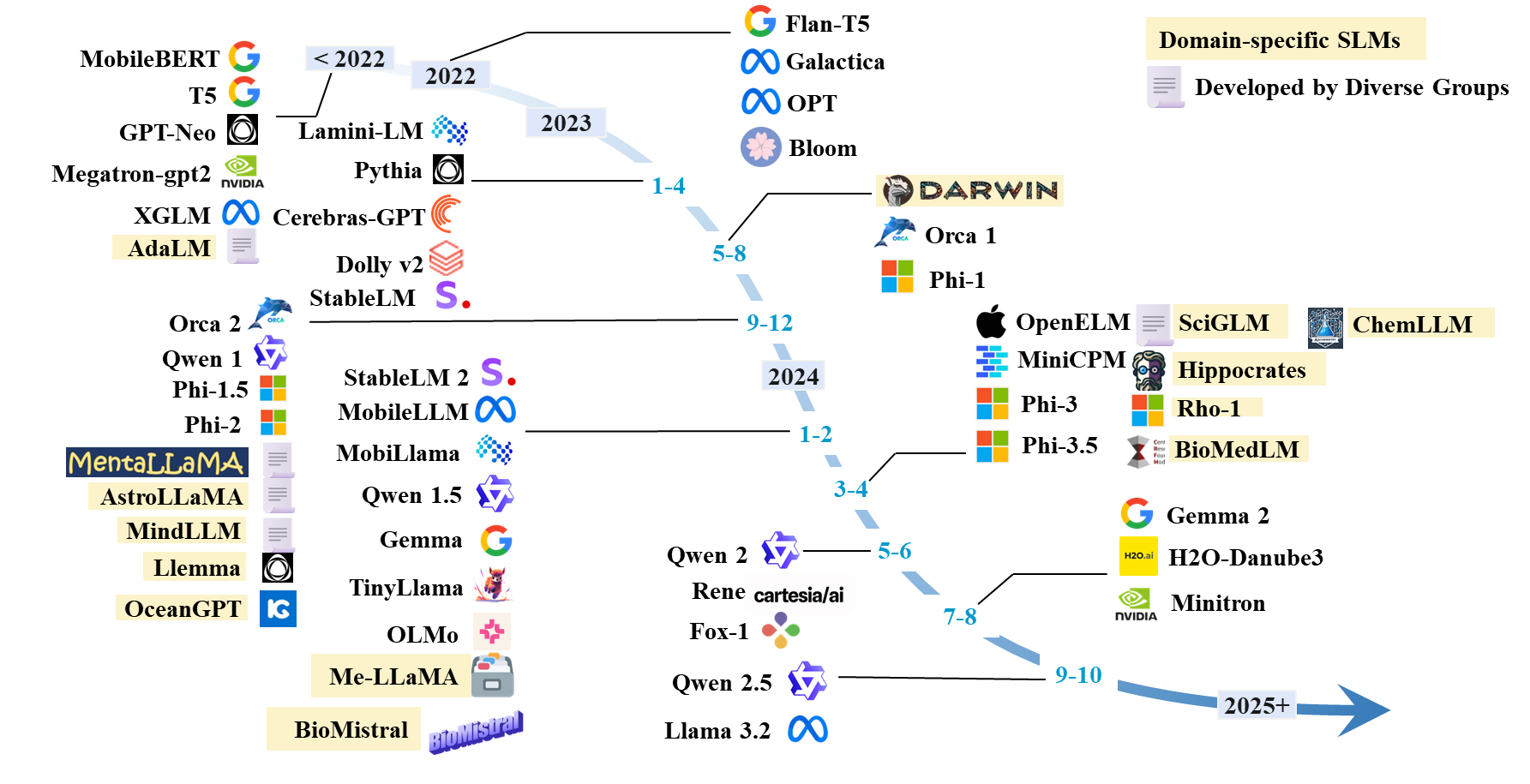
Figure 3 A timeline of existing small language models.
Definition of SLMs
Typically, language models with emergent abilities are classified as LLMs. However, there is no unified definition for SLMs. Some studies suggest that SLMs have fewer than 1 billion parameters and are usually equipped with about 6GB of memory on mobile devices. In contrast, others believe that SLMs can have up to 10 billion parameters, but these models typically lack emergent capabilities. Considering the application of SLMs in resource-constrained environments and for specific tasks, we propose a generalized definition: the parameter range of SLMs should be between the minimum size that can demonstrate emergent abilities for particular tasks and the maximum size that is manageable under resource constraints. This definition aims to integrate different perspectives and consider factors related to mobile computing and capability thresholds.
As the demand for SLMs grows, current research literature covers various aspects of SLMs, including training techniques optimized for specific applications such as quantization-aware training and selective architectural component selection. Although the performance of SLMs is recognized, potential credibility issues, such as the risks of hallucination and privacy breaches, still need attention. There is a lack of comprehensive surveys thoroughly exploring these aspects of SLMs in the era of large language models (LLMs). This paper aims to provide an in-depth survey, analyzing various aspects of SLMs during the LLM era and their future development. For more details, see our full paper.